Artiklar som i IDG:s ordlista handlar om statistik i allmänhet. Det är en underavdelning av kategorin matematik. Artiklar om webbstatistik finns i kategorin webbstatistik. Se också kategorin sannolikhet.
– normalization – om relationsdatabaser – att se till att en relationsdatabas är väl utformad. Den ska undvika dubblering av information, vara lätt att göra ändringar i (man ska bara behöva ändra på ett ställe) och lätt att göra sökningar i (man ska kunna förutse var information finns). – Ett krav är att varje tabell ska innehålla minst en nyckel, det vill säga ett värde som entydigt identifierar varje rad (till exempel personnummer i ett personregister): i varje tabell ska det alltså finnas minst en kolumn där samma värde inte får förekomma två gånger
– när det gäller statistik är normalisering att göra värden jämförbara, till exempel att se till att allt material räknas om till samma måttenheter och att tidsperioder (till exempel räkenskapsår) sammanfaller. – En form av normalisering är formatanpassning(canonicalization) – Se också datapreparering.
i statistik: värdet i mitten – om man sorterar alla värden i ett statistiskt material i storleksordning så är medianen det värde som står exakt i mitten. Om talserien innehåller ett jämnt antal värden är medianen medelvärdet av de två värdena i mitten. – Medianen är mest belysande när det gäller ojämnt fördelade värden, till exempel 1,1,2,2,9: medianen är 2. Detta kan säga mer än medelvärdet, eftersom medelvärdet (2,5) dels inte ingår i talserien, dels förskjuts av ett enstaka utstickande värde (9). Ett praktiskt exempel är bedömning av inkomsterna i ett bostadsområde: om det finns 99 låginkomsttagare och en miljardär hamnar medelinkomsten i området på en nivå som inte motsvarar någons faktiska inkomst. Tar man i stället medianinkomsten får man ett mer representativt värde som inte påverkas av miljardärens inkomst. – Om man har värden som inte går att sortera i storleksordning kan man i stället ta typvärdet.
(baseline) – allmänt: en tänkt nivå som man utgår från när man mäter eller förändrar något. Vanligtvis utgår man, när man talar om baslinje, inte från värdet noll utan från värden som motsvarar utgångsläget. Syftet är att kunna mäta förändringar:
– ursprunglig nivå, basnivå – utgångsvärden för en förändringsprocess: kvantitativ beskrivning av det som ska förändras sådant det är innan förändringen påbörjas;
– motsvarande för olika slags försöksverksamhet, till exempel testning av läkemedel;
– i systemutveckling även: etappmål – en på förhand definierad nivå i utvecklingsarbetet då man anses ha klarat av en del och kan gå vidare till nästa. Man har alltså nått baslinjen för nästa nivå;
– basår, basperiod – tidpunkt som man utgår från vid jämförelser;
– i typografi: den tänkta linjen längs nederkanten på bokstäver som a, b, c, d. – Några bokstäver som g och j har en del som hänger nedanför baslinjen, ett underhäng;
– baseline budgeting – basbudgetering – budgetering som utgår från föregående års budget med justering för inflationen (och eventuellt andra kända faktorer);
– grundprinciper (för engelska baseline) – ståndpunkter som man inte kan ge efter från;
– baseline document – utkast, underlag, avsett för förhandlingar;
– i it: mätning av en kontinuerlig signal (som musik) med jämna mellanrum; när det gäller inspelning av musik tiotusentals gånger i sekunden. (Man digitiserar ljudet.) Antalet mätningar per sekund kallas för samplingsfrekvens. Samplingsfrekvensen är för CD‑inspelningar 44 100 hertz. Man utgår från att ingen betydelsefull information går förlorad mellan mätningarna, förutsatt att de sker tillräckligt tätt. (Se Nyquists lag.) Sampling är en förutsättning för att analoga signaler ska kunna behandlas med digital teknik;
– i statistik innebär sampling att man tar stickprov ur en större grupp och sedan utgår från att slutsatser om den undersökta, mindre gruppen också gäller för den större gruppen.
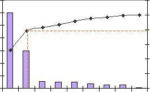
Paretodiagram som åskådliggör Pareto-principen. Den svarta linjen, som planar ut, visar ackumulerat värde.
”20 procent av orsakerna står för 80 procent av effekterna.” – Paretoprincipen säger att 20 procent av kunderna står för 80 procent av försäljningen, de rikaste 20 procenten av befolkningen äger 80 procent av alla pengar, 20 procent av problemen tar 80 procent av tiden att lösa. – Paretoprincipen är därför också känd som 80–20‑regeln. Det är en iakttagelse som stämmer ungefär i många fall, inte en exakt lag. Paretoprincipen kan gälla i flera led: inom de 20 procenten står återigen 20 procent av orsakerna för 80 procent av effekterna: alltså fyra procent mot 96 procent. Och så vidare. – Ett diagram som visar fördelningen med orsakerna (i bred bemärkelse) på längdaxeln och effekterna på höjdaxeln kallas för Paretodiagram. Ett Paretodiagram som åskådliggör Paretoprincipen har en stor kropp i ena änden (80 procent av effekterna på höjdaxeln) medan större delen av diagrammet är en lång smal svans (20 procent av effekterna på höjdaxeln, men 80 procent av orsakerna på längdaxeln). – I företagsekonomi har principen använts som motivering för att satsa på de 20 procenten och strunta i resten. Detta har ifrågasatts – se den långa svansen. – På engelska: the Pareto principle. – Se också drakkung, potenslag, svart svan och Zipfs lag. – Läs också om DSDM. – Principen är uppkallad efter den italienska ekonomen och industrialisten Vilfredo Pareto (1848—1923, se Wikipedia).