Artiklar som i IDG:s ordlista handlar om statistik i allmänhet. Det är en underavdelning av kategorin matematik. Artiklar om webbstatistik finns i kategorin webbstatistik. Se också kategorin sannolikhet.
en svensk stiftelse som sprider information om global utveckling med hjälp av grafisk presentation av statistiska data. – Gapminder sålde 2007 programmet Trendalyzer till Google. Stiftelsen grundades 2005 av Ola Rosling, Anna Rosling Rönnlund och Hans Rosling (1948–2017). Programmet Trendalyzer utvecklades av Ola Rosling, men det blev känt genom Hans Roslings föredrag. – Se gapminder.org.
ett program för grafisk representation av data. – Trendalyzer utvecklades av Ola Rosling för stiftelsen Gapminder, som 2007 sålde programmet till Google. Google tillhandahåller det under namnet Public data explorer(länk). Programmet är förinställt för att hantera fem variabler. De visas på x‑axel och y‑axel samt som bubblor i olika storlekar och färger och på en glidande tidsaxel. Programmet levereras med en uppsättning data om global utveckling, men användaren kan mata in egna data.
avsiktlig sammanblandning av personuppgifter i syfte att anonymisera dem. – Perturbation används vid statistisk analys av integritetskänsliga data. – Vanlig pseudonymisering, det vill säga att man tar bort namn och andra uppgifter som direkt kan knytas till en bestämd person, anses osäker. Det är nämligen ändå enkelt att koppla anonymiserade data om en person till den personen om man har tillgång till det ursprungliga registret eller annan lämplig information. Perturbation innebär att man låter vissa uppgifter byta plats mellan personer på ett sätt som gör att den statistiska analysen ändå blir giltig. A får B:s adress, B får C:s ålder och så vidare. Man kan också ändra en del mätvärden på ett systematiskt sätt som inte påverkar slutresultatet. Liknande metoder används också för att hemlighålla information i datakommunikation. – En mer allmän betydelse av engelska perturbation är störning, avvikelse från förväntat värde. – Läs också om datamaskering, k‑anonymitet och kvasiidentifierare.
antagandet att alla data i statistisk analys kan passas in i en normalfördelningskurva, och att varje värde som tillkommer är oberoende av de tidigare. Men så är ofta inte fallet. – Förkortas IID, iid eller i. i. d. På svenska: oberoende och likafördelade, förkortat OLF.– Se också svart svan och ludiskt felslut.
minskning av antalet uppgifter i en datamängd; sammanslagning av värden som ligger nära varandra. Uttrycket kommer av engelska bin – korg, behållare, soptunna – man lägger värden som ligger nära varandra ”i samma korg”:
– data binning innebär att värden som ligger nära varandra byts ut mot ett enhetligt värde, vanligtvis det centrala. Exempel: alla värden mellan 9,5 och 10,5 byts ut mot 10. Avrundning kan alltså ses som en form av binning;
– i digital bildbehandling: det att en grupp bildpunkter (pixlar) ersätts med en enda bildpunkt. 2⨯2 eller 3⨯3 bildpunkter kan till exempel ersättas med en enda bildpunkt. Vanligtvis blir det då ett medelvärde av de ingående bildpunkternas färgtoner. Detta kan underlätta bildanalys och göra bilden tydligare, och det är nödvändigt om bilden ska förminskas;
– phone binning (skämtsamt): att hålla en kikare framför objektivet på en mobiltelefons kamera. Man använder alltså kikaren som teleobjektiv;
– to bin kan också betyda att kasta bort (”lägga i det runda arkivet”, the bin).
(affinity analysis) – sökning efter statistiska samband i stora datamängder. Alltså en typ av datautvinning. – Affinitet är i marknadsföring ett mått på hur mycket en målgrupp är intresserad av en produkt eller tjänst. Om målgruppen är mer intresserad av produkten än genomsnittet av befolkningen är affiniteten hög. Hög affinitet kan alltså antas ge gott gensvar på reklamen. – Ordet affinitet används också i andra sammanhang med besläktade betydelser.
en kurva som beskriver den fördelning av värden som i statistisk teori anses mest sannolik. – Kurvan har formen av en kulle eller en kyrkklocka och kallas därför på engelska för bell curve. De värden som ligger runt medelvärdet är vanligast, och antalet större och mindre värden är ungefär samma på båda sidor om mitten – kurvan är symmetrisk. – Exempel: De flesta vuxna personer är runt medellängd, medan det finns få som är ovanligt långa eller ovanligt korta. En kurva över den vuxna befolkningens kroppslängd med kroppslängd på den liggande axeln och antal personer på den stående axeln skulle likna en normalfördelningskurva. Kullen eller bulan i mitten representerar de medellånga. ”Svansarna” längst till vänster och höger representerar antalet mycket korta respektive mycket långa. Det finns inga vuxna som är tre meter, så om man lägger till slumpmässigt utvalda personer till underlaget för kurvan förändras den inte mycket. – Från början var kurvan en rent matematisk konstruktion, uttänkt av matematikern Carl Friedrich Gauss. Den visar sannolikheten för olika utfall i teoretiska experiment, som när man till exempel singlar slant många gånger. (Ju fler gånger man gör det, desto mer sannolikt att det blir ≈50 procent krona och ≈50 procent klave.) Det var först senare som normalfördelningskurvan fick användning i tillämpad statistik. – I boken Den svarta svanen (2012, The black swan, 2007) kritiserade Nassim Nicholas Taleb användningen av normalfördelningskurvan i analys och prognoser. Han påpekar att den inte speglar sådant som fördelningen av pengar. – Se också independently and identically distributed och ludiskt felslut. – På engelska: normal distribution curve, bell curve eller gaussian curve; ofta bara Gaussian.
det vanligaste värdet i ett statistiskt material. Skiljer sig ofta både från medelvärdet och medianen. – Påhittat exempel: Svenska kvinnor föder i genomsnitt 1,3 barn, medianen är ett barn, men typvärdet är två barn. Typvärdet är särskilt användbart när man analyserar sådant som inte kan anges i siffror, som könstillhörighet eller djurarter. – På engelska: mode.
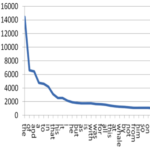
Diagram över antal förekomster av de vanligaste orden i engelska. Den snabbt fallande kurvan som senare planar ut illustrerar Zipfs lag.
säger att frekvensen av ett värde i en stor mängd data ofta står i proportion till värdets plats i rangordningen. – Det vanligaste värdet brukar vara ungefär dubbelt så vanligt som det näst vanligaste, ungefär tre gånger så vanligt som det värde som är nummer tre på listan, och så vidare. – Lagen är uppkallad efter språkvetaren George Kingsley Zipf (1902—1950, se Wikipedia), som upptäckte att den gäller för ordfrekvenser i stora textmassor. – Exempel: i modern engelska är the det vanligaste ordet, 6,9 procent av alla ord. Näst vanligast är of med 3,6 procent och tredje vanligast är and med 2,8 procent. Som synes följer fördelningen inte Zipfs lag exakt, men det påstod Zipf inte heller att den skulle göra. Hans lag beskriver en tendens. – Lagen kallas också för Zipf‑Mandelbrots lag efter Benoit Mandelbrot†, som utvidgade principens tillämpning. Samma förhållande mellan plats i rankinglistan och frekvens av förekomster har nämligen iakttagits för andra företeelser. Man har också upptäckt att förhållandet inte alltid är rakt (alltså inte följer mönstret 1/1, 1/2, 1/3…), utan att nämnaren ofta måste multipliceras med en konstant för att lagen ska gälla. Alltså till exempel 1/4, 1/8, 1/12… – Zipfs lag är en potenslag(power law). – Lagen har också tillämpats på analys av sociala nätverk. Enkelt uttryckt: de kontakter som vi har minst kontakt med är praktiskt taget värdelösa. – Se också drakkung, långa svansen, svart svan och Paretoprincipen.